TensorFlow é un marco (framework) desenvolto por Google que proporciona todas as ferramentas necesarias para construír, adestrar e despregar modelos de aprendizaxe automática. É moi poderoso e flexible, pero pode ser algo complicado para principiantes porque require moitos coñecementos técnicos.
Keras é unha biblioteca que funciona sobre TensorFlow . O seu propósito é facer máis fácil e accesible o desenvolvemento de redes neuronais.
Actividades de aprendizaxe
Actividade 1: O teu primeiro modelo con Keras
◦ Obxectivo: Aprender como funciona un modelo de rede neuronal con Keras. ◦ Instrución: Crear e adestrar unha rede neuronal básica que prediga se un número é maior ou menor que 5.
Paso 1: Imos crear e adestrar un modelo básico de rede neuronal para entender o concepto.
Código Python: Rede neuronal básica predí se un número é >=5
# Importamos as bibliotecas necesarias.
# TensorFlow proporciónanos as ferramentas para crear e adestrar redes neuronais.
print("Importando TensorFlow e Keras para crear e adestrar redes neuronais.")
import tensorflow as tf
# Sequential e Dense son partes de Keras (que está integrado en TensorFlow).
# Sequential permítenos crear un modelo de rede neuronal agregando capas en orde.
# Dense engade capas densas ao noso modelo, que son capas onde cada neurona está conectada con todas as da capa anterior.
print("Importando Sequential e Dense de Keras para construír a rede neuronal.")
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Importamos NumPy, que é unha ferramenta para traballar con números e xerar datos de proba.
print("Importando NumPy para xerar datos de entrada.")
import numpy as np
# Xeramos datos de entrada para adestrar o noso modelo.
# Creamos 1000 números aleatorios entre 0 e 9.
# Estes números serán os datos que o modelo usará para aprender.
print("Xerando 1000 números aleatorios entre 0 e 9 para adestrar o modelo.")
datos_entrada = np.random.randint(0, 10, size=1000)
# Creamos as etiquetas (os resultados correctos) para os nosos datos.
# Se un número é maior que 5, será etiquetado cun 1 (verdadeiro).
# Se é menor ou igual a 5, será etiquetado cun 0 (falso).
# Estas etiquetas axudan ao modelo a 'saber' que respostas son correctas durante o adestramento.
print("Etiquetando os datos: se un número é maior que 5, etiquetarase cun 1 (verdadeiro); se non, cun 0 (falso).")
etiquetas = (datos_entrada > 5).astype(int)
# Creamos o modelo usando Keras.
# Usamos Sequential para definir a estrutura da rede neuronal, que aquí ten dúas capas.
print("Configurando o modelo de rede neuronal con dúas capas.")
modelo = Sequential()
# Primeira capa da rede neuronal:
# Dense(10): Creamos unha capa con 10 neuronas.
# input_shape=(1,): Cada entrada é un número único (por iso o tamaño de entrada é 1).
# activation='relu': A función de activación 'relu' axuda ao modelo a aprender patróns complexos.
print("Engadindo a primeira capa con 10 neuronas e función de activación 'relu'.")
modelo.add(Dense(10, input_shape=(1,), activation='relu'))
# Segunda capa da rede neuronal:
# Dense(1): Só ten unha neurona porque o noso modelo debe clasificar entre dúas opcións (1 ou 0).
# activation='sigmoid': A función de activación 'sigmoid' converte a saída da rede nun valor entre 0 e 1,
# ideal para problemas de clasificación binaria.
print("Engadindo a segunda capa cunha neurona de saída e función de activación 'sigmoid'.")
modelo.add(Dense(1, activation='sigmoid'))
# Compilamos o modelo.
# Isto configura como o modelo aprenderá durante o adestramento.
print("Compilando o modelo con optimizador 'adam' e función de perda 'binary_crossentropy'.")
modelo.compile(
optimizer='adam', # Adam é un optimizador avanzado que axusta os cálculos do modelo para mellorar a súa precisión.
loss='binary_crossentropy', # A función de perda binary_crossentropy mide o erro do modelo ao predicir dúas categorías.
metrics=['accuracy'] # Utilizamos a métrica 'accuracy' para monitorizar que tan preciso é o modelo.
)
# Adestramos o modelo.
# Este é o paso onde o modelo analiza os datos e axusta os seus parámetros para aprender.
print("Adestrando o modelo con 10 iteracións sobre os datos de entrada.")
modelo.fit(
datos_entrada, # Datos de entrada que o modelo procesará.
etiquetas, # Respostas correctas asociadas aos datos de entrada.
epochs=10, # O modelo verá os datos completos 10 veces durante o adestramento.
batch_size=32 # Dividimos os datos en bloques de 32 números para procesalos máis eficientemente.
)
# Notas para o alumnado:
# 1. Parabéns! Acabas de adestrar a túa primeira rede neuronal.
print("Parabéns! Acabas de adestrar a túa primeira rede neuronal.")
# 2. O modelo agora é capaz de predicir se un número aleatorio é maior ou menor que 5.
print("Agora o modelo pode predicir se un número aleatorio é maior ou menor que 5.")
# 3. Intenta cambiar os datos (por exemplo, aumentando o rango de números) e observa como afecta ao modelo.
print("Intenta modificar os datos de entrada e observa como afecta ao modelo.")
# Solicitar ao alumnado que ingrese un número para predicir.
print("\nAgora que o modelo está adestrado, imos facer unha predición.")
numero = int(input("Introduce un número entre 0 e 9: "))
# Realizar a predición co modelo.
print("\nProcesando o número introducido...")
prediccion = modelo.predict(np.array([numero]))[0][0]
# Interpretar a saída.
print("\nInterpretación da predición:")
print(f"O modelo deu unha saída de {prediccion:.2f}, que representa a probabilidade de que o número sexa maior que 5.")
if prediccion > 0.5:
print("Segundo o modelo, este número probablemente sexa maior que 5.")
else:
print("Segundo o modelo, este número probablemente sexa menor ou igual que 5.")
# Mensaxe final para o alumnado.
print("\nParabéns! Agora comprendes como unha rede neuronal pode facer predicións baseadas nos datos.")
print("Podes probar con outros números e ver como cambia a saída!")
Propóñoche:
Intenta aumentar os datos de adestramento e observa como afecta ao modelo.
Que o programa che pida datos a predecir ata que queiras sair (con while: True)
Este programa está deseñado para adestrar unha rede neuronal moi básica que clasifica números aleatorios como maiores ou menores (ou iguais) a 5. Durante o adestramento, o modelo verá os datos 10 veces (10 épocas ou epoch). Cada vez, axustará os seus parámetros para minimizar o erro. Na consola mostraranse resultados como:
Unha vez finalizado, o modelo estará "adestrado" para predicir se un número dado é maior ou menor que 5. Poderás probalo con novas entradas para verificar a súa eficacia.
Por exemplo, no mesmo caderno de Colab, poderías usar este código e ir cambiando o 7 por outros números:
import numpy as np
# Predecimos o 7 predicion = modelo.predict(np.array([7])) print(predicion)
#Esto ddebería dar unha probabilidade cercana a 1, se o modelo funciona ben #Se probas con un número como 3, deberías obter un valor cercano a 0, se o modelo funciona ben.
Explicación do programa:
Importando as bibliotecas necesarias
Un programa de redes neuronais precisa ferramentas para traballar con datos e construir modelos. O código primeiro importa:
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense import numpy as np
TensorFlow: É unha biblioteca que facilita a creación e adestramento de redes neuronais.
Keras: Unha ferramenta dentro de TensorFlow que permite construír modelos de forma sinxela.
NumPy: Axuda a manexar números e crear datos de proba.
Creando datos de entrada
Unha rede neuronal necesita exemplos para aprender. Neste caso, creamos 1.000 números aleatorios entre 0 e 9 para ensinarlle á rede a distinguir entre números maiores e menores que 5.
Exemplo : Imaxina que un neno aprende a diferenciar entre "alto" e "baixo". Se lle dis que alguén con máis de 1,70m é alto e alguén con menos de 1,70m é baixo, comezará a usar esa regra para clasificar persoas. Aquí a rede neuronal está a aprender algo similar: números maiores que 5 serán "1" (verdadeiro) e números menores ou iguais a 5 serán "0" (falso).
Construíndo o modelo
O modelo funciona como unha fábrica de decisións. Usamos Keras para construír unha rede neuronal con dúas capas:
Exemplo : Imaxina que estás aprendendo a lanzar unha pelota á canastra. Cada vez que fallas, tes que analizar por que e mellorar o próximo intento. O optimizador "adam" é como un adestrador que te axuda a mellorar os tiros.
Adestrando o modelo
Finalmente, usamos os datos para adestrar á rede neuronal:
Exemplo : Se aprendes a tocar a guitarra, non basta con tocar só unha vez. Necesitas moitas prácticas para mellorar. Aquí, a rede neuronal fai o mesmo: aprende a clasificar números repetindo o proceso 10 veces (epochs) e procesando datos en bloques de 32 (batch_size).
Agora tes unha idea básica de como funciona unha rede neuronal e como usamos Keras para creala. Este modelo que construímos aprende a distinguir entre números maiores e menores que 5. Poderíamos melloralo con máis datos ou cambiando as capas, pero este é un gran primeiro paso.
Paso 2: Graficando a perda e a precisión
Creación propia. Resultado das funcións erro e precisión(CC BY-SA)
E se queremos graficar e comprender a evolución en cada epoch das funcións loss e accuraty, podemos usar este programa, que as grafica, e ademáis ten unha entrada dinámica pedíndoche datos para predicir ata que decidas sair. Como podes comprobar, cada vez que o executas as gráficas cambian, a aprendizaxe é dinámica.
A gráfica mostra o comportamento do modelo durante o adestramento a través de dúas métricas fundamentais: erro (loss) e precisión (accuracy).
Gráfica da función de perda (Loss ou erro)
Que nos di esta curva?
No inicio do adestramento (época 0), o erro do modelo era alto, arredor de 1.2.
A medida que avanzan as épocas, o erro diminúe de forma constante, chegando a aproximadamente 0.5 na última época.
Isto significa que o modelo aprende a distinguir mellor entre números maiores e menores que 5 a medida que vai "practicando".
Interpretación: A diminución do erro indica que o modelo está axustando correctamente os pesos internos das neuronas, reducindo os fallos nas predicións.
Gráfica da precisión (Accuracy)
Que nos di esta curva?
A precisión inicial era baixa, arredor do 50%, o que significa que ao comezo o modelo tomaba decisións case ao azar.
Ao longo do adestramento, a precisión mellora progresivamente, chegando a aproximadamente 80%.
Isto confirma que o modelo está aprendendo e facendo predicións máis acertadas.
Interpretación: A subida da precisión reflicte que o modelo identifica cada vez mellor os patróns dos datos e realiza clasificacións máis correctas.
O que observamos é un comportamento esperado nun modelo de rede neuronal simple:
Baixa o erro → O modelo reduce os fallos nas predicións.
Sube a precisión → Cada vez acerta mellor ao decidir se un número é maior ou menor que 5.
Despois de varias épocas, mellora a súa capacidade de clasificación.
Este proceso demostra como unha rede neuronal pode aprender de datos e optimizar as súas decisións co tempo.
Propóñoche:
Probar a aumentar o número de épocas e observar se mellora aínda máis ou chega a un punto de estancamento no que xa NON aprende máis.
Paso 3 : Agora aprenderás a avaliar o modelo según a perda e precisión durante o adestramento e a validación
A validación refírese a un conxunto de datos que se usa durante o adestramento do modelo para verificar o seu rendemento.Axuda a axustar parámetros da rede neuronal. Úsase para previr sobreaxuste (é dicir, que o modelo se aprenda demasiado os datos de adestramento e non xeralice ben). Con este programa, podes graficalos, como comprobarás, cada vez que o executas, as gráficas cambian, xa que a prendizaxe é dinámica.
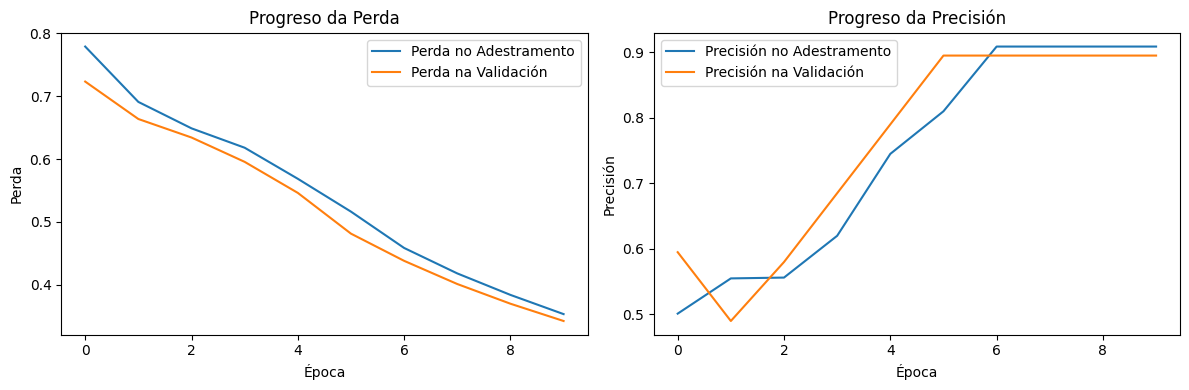
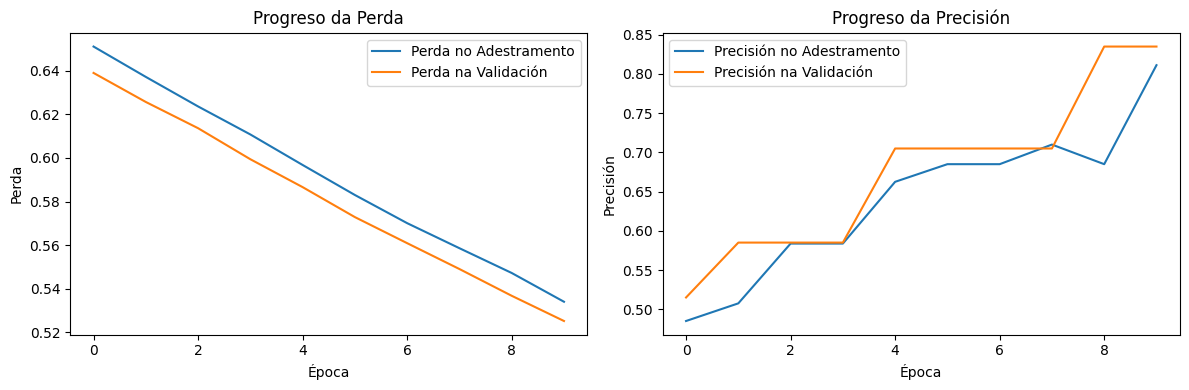
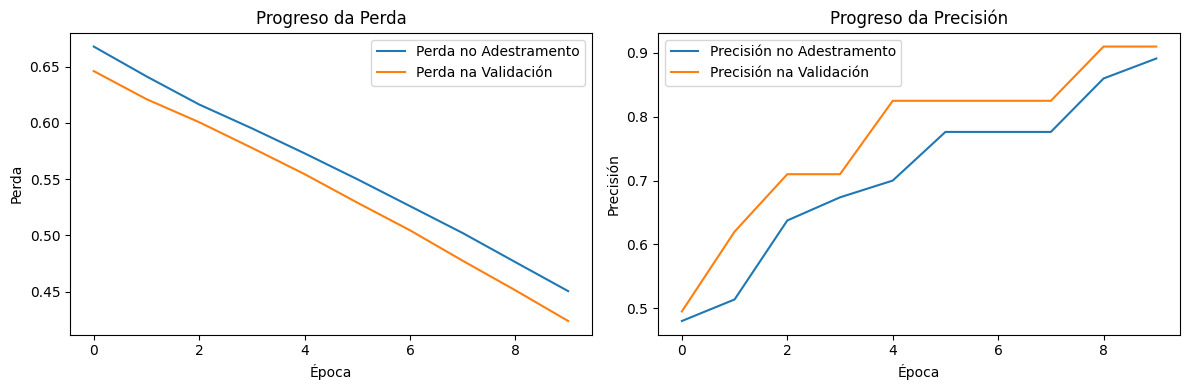
Creación propia. Resultado da perda e precisión durante o adestramento e a validación(CC BY-SA)
A gráfica mostra o progreso da perda e da precisión durante o adestramento do modelo.
Gráfico da perda (Loss)
Liña azul: Mostra como se reduce o erro do modelo nos datos utilizados para adestralo. A medida que avanzan as épocas, a liña descende de forma constante, indicando que o modelo está a aprender a clasificar mellor os datos.No inicio do adestramento, a perda no adestramento era arredor de 0.700 e diminúe progresivamente ata aproximadamente 0.550 despois de 10 épocas.
Liña laranxa: Representa o erro do modelo en datos separados que non se usan no adestramento directo. Unha tendencia descendente aquí indica que o modelo non só está a mellorar nos datos de adestramento, senón que tamén xeneraliza ben en datos novos. A perda na validación comeza arredor de 0.650, seguindo un patrón semellante e alcanzando aproximadamente 0.525 ao final.
Ambas as liñas (adestramento e validación) diminúen coas épocas, o que é un sinal de que o modelo está a mellorar.
Se a liña de validación comezase a aumentar mentres a de adestramento diminuíse, indicaría sobreaxuste (o modelo memoriza os datos de adestramento pero falla en xeneralizar).
Esta gráfica indica que o modelo está aprendendo correctamente, reducindo os erros progresivamente.
Gráfico da precisión (Accuracy)
Liña azul : Mostra que tan ben o modelo clasifica os datos de adestramento. A liña ascende, o que significa que o modelo está a mellorar e acertando cada vez máis cos datos que viu antes. A precisión no adestramento comeza arredor de 0.50, aumentando ata 0.75 despois de 10 épocas.
Liña laranxa : Mostra o rendemento do modelo en datos non vistos durante o adestramento. Unha tendencia ascendente aquí, indica que o modelo xeneraliza ben e estase volvendo eficaz tamén para datos novos. A precisión na validación inicia con valores próximos a 0.50, subindo ata 0.80 ao final.
Ambas as liñas aumentan coas épocas, o cal é ideal e mostra que o modelo está a aprender correctamente.
Se as liñas estabilízanse ou se achegan, significa que o modelo alcanzou o seu límite de aprendizaxe para esta configuración.
Ambos os gráficos son ferramentas clave para avaliar o rendemento do modelo. Neste caso:
O modelo mellora continuamente en ambas as métricas (baixa a perda e sobe a precisión).
As liñas de adestramento e validación compórtanse de maneira similar, o que indica que non hai problemas de sobreaxuste nin de mala xeneralización.
O que vemos nestas gráficas confirma que o modelo mellora progresivamente, tanto en perda como en precisión, o que indica que está aprendendo correctamente sen sobreaxuste significativo. Se quixeramos melloralo, poderiamos aumentar as épocas ou modificar a estrutura das capas para optimizar os resultados.
Propóñoche que investigues:
Como afecta aumentar as epoch?Mellora continuamente a medida que subes as epoch?
Explicación dos posibles problemas que podes detectar nas gráficas anteriores
Se o modelo non está aprendendo correctamente, a gráfica anterior mostrará certos patróns que indican problemas na aprendizaxe.
Aquí che explico os signos clave e como corrixilos:
O erro (Loss) non diminúe ou diminúe moi lentamente
Que significa? Se a curva de perda se mantén alta e apenas baixa coas épocas, significa que o modelo non está mellorando nin aprendendo a distinguir correctamente entre números maiores e menores que 5.
Solucións:
Revisar os datos: Se os datos teñen ruído ou non están ben distribuídos (sesgados=todos os valores parecidos, non hai exemplos suficientes de todos os tipos) , o modelo pode ter problemas para aprender.
Axustar a taxa de aprendizaxe (learning rate) no optimizador adam, probando valores menores (por exemplo, 0.001 en vez de 0.01).
Engadir máis neuronas ou capas ocultas para que o modelo poida identificar patróns mellor.
A precisión (Accuracy) se mantén preto do 50% e non sobe
Que significa? Se o modelo mantén a precisión ao redor do 50%, está tomando decisións ao azar, como se fose unha moeda. Isto indica que non está atopando patróns reais nos datos.
Solucións:
Cambiar o tipo de activación (relu e sigmoid) ou probar outras, como tanh.
Ver se os datos están equilibrados: Se hai moitos máis números maiores que 5 que menores, o modelo pode sesgarse cara a unha categoría.
Incrementar as épocas (epochs) para que o modelo teña máis tempo de aprendizaxe.
A perda na validación (val_loss) aumenta mentres a perda no adestramento (loss) diminúe
Que significa? Este patrón indica sobreaxuste, é dicir, que o modelo aprendeu demasiado os datos de adestramento e non xeneraliza ben en datos novos.
Solucións:
Reducir a complexidade do modelo (menos neuronas ou capas).
Usar regularización (dropout) para evitar que o modelo se adapte demasiado aos datos de adestramento.
Aumentar os datos para que o modelo aprenda con exemplos máis variados.
A curva de precisión (accuracy) fluctúa moito en cada época
Que significa? Se a precisión ten moitas subidas e baixadas bruscas, significa que o modelo non está tendo unha aprendizaxe estable.
Solucións:
Diminuír a taxa de aprendizaxe para que os axustes sexan máis suaves.
Aumentar o tamaño do lote (batch_size) para que o modelo traballe con máis datos á vez e estabilice a aprendizaxe.
As gráficas dan pistas visuais sobre como está aprendendo o modelo. Dependendo do problema que vexamos, podemos axustar hiperparámetros, revisar os datos ou modificar a arquitectura do modelo para mellorar os resultados.
Que é unha rede neuronal?
Unha rede neuronal é un tipo de modelo matemático inspirado no funcionamento do cerebro humano. Está composta por unidades chamadas neuronas artificiais, que procesan datos e toman decisións baseándose en exemplos previos.
Imaxina que queres ensinar a un cativo a distinguir entre gatos e cans. Primeiro, amósalle fotos e explícalle cales son gatos e cales son cans. Pouco a pouco, comezará a recoñecelos por si mesmo.
Unha rede neuronal aprende de xeito similar: recibe datos, analiza exemplos anteriores e mellora as súas predicións co tempo.
Sequential é unha forma fácil de construír redes neuronais en Keras, onde as capas se engaden en orde, unha tras outra.
Exemplo : Imaxina unha liña de montaxe nunha fábrica de coches. O coche pasa por distintas etapas (chasis, pintura, motor...), unha tras outra, ata completarse.
En Sequential, as capas de neuronas funcionan do mesmo xeito: cada capa recibe información da anterior e pásaa á seguinte.
Código básico:
from tensorflow.keras.models import Sequential # poñemos a disposición o tipo de modelo Sequential
modelo = Sequential() # Creamos un modelo Sequential
Dense engade capas densamente conectadas a unha rede neuronal, onde cada neurona está conectada con todas as neuronas da capa anterior.
Exemplo : Imaxina unha aula onde cada estudante fala con todos os demais. Así, todos teñen acceso á mesma información.
En Dense, cada neurona ten conexión directa con todas as da capa anterior.
Código básico:
from tensorflow.keras.layers import Dense # poñemos a disposición o tipo de capas Dense
modelo.add(Dense(10, input_shape=(1,), activation='relu')) #engadimos ó modelo unha capa Dense con esas características
Capa con 10 neuronas Aquí:
10 → Número de neuronas na capa.
input_shape=(1,) → Indica que cada entrada é un número único.
activation='relu' → Función de activación que explicarei a continuación.
A función de activación decide como responderán as neuronas aos datos. É como un filtro que transforma os valores de saída.
Tipos comúns de activación:
ReLU (relu) → Mantén só valores positivos.
Sigmoid (sigmoid) → Converte valores nun rango de 0 a 1, útil para clasificación.
Código básico:
modelo.add(Dense(10, activation='relu')) # Usa ReLU para identificar patróns
modelo.add(Dense(1, activation='sigmoid')) # Usa Sigmoid para clasificación binaria, 6é ou non é >=5
Adam é un optimizador que mellora a aprendizaxe do modelo axustando os cálculos para obter mellores resultados.
Exemplo : Pensa en aprender a lanzar unha pelota a unha canastra. Primeiro tiras e ves onde fallaches. Logo, axustas a forza e a dirección.
Adam fai algo parecido: axusta os pesos das conexións da rede para reducir os erros.
Código básico:
modelo.compile(optimizer='adam')
Loss (Perda): É unha medida de que tan mal está a facer o modelo as súas predicións.
Pensa na perda como un marcador de erro: se o modelo comete erros grandes, o valor de loss será alto, pero se está a predicir correctamente, o valor será baixo.
Exemplo : Imaxínate que un amigo tenta adiviñar a temperatura de hoxe. Se di que fai 30°C pero realmente fai 10°C, a diferenza é grande, así que a perda será alta. Se adiviña que fai 12°C, a perda será menor porque estivo máis preto da verdade.
Accuracy (Precisión): É a porcentaxe de predicións correctas que fai o modelo.
En termos simples, mide que tan frecuentemente o modelo acerta.
A precisión debería incrementarse con cada época, comezando probablemente cun valor baixo (50%) e mellorando cara ao 100% (ou preto)
Exemplo : Se en 100 intentos o teu amigo acerta a temperatura 80 veces, entón a súa accuracy (precisión) é do 80%.
Código Python: Graficando loss e accuraty en modelo básico con Keras para predicir se un número é >=5
# Importamos as bibliotecas necesarias.
print("Estou chamando ás bibliotecas de TensorFlow e NumPy...") # Impresión explicativa
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import matplotlib.pyplot as plt
# Xerar datos de entrada para adestrar o modelo.
print("Xerando datos de entrada...") # Impresión explicativa
datos_x = np.random.randint(0, 10, size=1000) # Números aleatorios entre 0 e 9.
datos_y = (datos_x > 5).astype(int) # Etiquetas: 1 se o número é maior que 5, 0 en caso contrario.
# Crear o modelo usando Keras.
print("Creando o modelo da rede neuronal...") # Impresión explicativa
modelo = Sequential([
Dense(10, input_shape=(1,), activation='relu'), # Primeira capa: 10 neuronas, activación 'relu'.
Dense(1, activation='sigmoid') # Segunda capa: 1 neurona, activación 'sigmoid'.
])
# Imprimir as características da rede neuronal.
print("Características da rede neuronal:")
print(f"Modelo: {modelo.name}")
print(f"Número de capas: {len(modelo.layers)}")
print("Detalles das capas:")
for i, layer in enumerate(modelo.layers):
print(f" Capa {i+1}:")
print(f" Tipo: {type(layer).__name__}")
print(f" Número de neuronas: {layer.units}")
print(f" Activación: {layer.activation.__name__}")
# Compilamos o modelo.
print("Compilando o modelo para o adestramento...") # Impresión explicativa
modelo.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
# Adestramos o modelo.
print("Adestrando o modelo... Isto pode levar algún tempo.") # Impresión explicativa
historia = modelo.fit(
datos_x,
datos_y,
epochs=10,
batch_size=32,
verbose=1 # Verbose=1 amosa información detallada do progreso.
)
print("¡Adestramento finalizado!") # Impresión explicativa
# Graficar loss e accuracy.
print("Xerando gráficos do erro (loss) e precisión (accuracy)...") # Impresión explicativa
plt.figure(figsize=(12, 6))
plt.ion()
# Gráfico da función de perda (loss).
plt.subplot(1, 2, 1)
plt.plot(historia.history['loss'], label='Loss', color='red')
plt.title('Erro (Loss) durante o adestramento')
plt.xlabel('Épocas')
plt.ylabel('Erro')
plt.legend()
plt.grid(True)
# Gráfico da precisión (accuracy).
plt.subplot(1, 2, 2)
plt.plot(historia.history['accuracy'], label='Accuracy', color='blue')
plt.title('Precisión (Accuracy) durante o adestramento')
plt.xlabel('Épocas')
plt.ylabel('Precisión')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.pause(0.1)
# Engadir un bucle para pedir números continuamente
print("Introduce números para predicir se son maiores que 5. Escribe 'sair' para rematar.")
while True:
entrada_usuario = input("Introduce un número ou escribe 'sair': ").strip().lower()
if entrada_usuario == "sair":
print("Programa finalizado. Ata logo!")
break
try:
numero_novo = int(entrada_usuario) # Convertir a número enteiro
resultado = modelo.predict(np.array([[numero_novo]])) # Predicir co modelo
print(f"A probabilidade de que o número {numero_novo} sexa maior que 5 é: {resultado[0][0]:.2f}")
except ValueError:
print("Por favor, introduce un número válido.")
Código Python: Predicir se un número é >=50
'''Neste caso, o modelo aprenderá a clasificar números en función do novo límite (50 en lugar de 5).
Poderás observar se a perda (loss) ou a precisión (accuracy) cambian drasticamente e analizar
como responde o modelo a esta nova configuración de datos.'''
# Cambiamos o rango de números xenerados, por exemplo, entre 0 e 99
datos_x = np.random.randint(0, 100, size=1000)
# Actualizamos as etiquetas para reflexar este novo rango
# Agora un número será etiquetado como 1 si é maior que 50, en lugar de 5
datos_y = (datos_x > 50).astype(int)
# Entrenamos novamente o modelo con estes novos datos
modelo.fit(
datos_x,
datos_y,
epochs=10,
batch_size=32
)
import numpy as np
# Predecimos o 97
predicion = modelo.predict(np.array([97]))
print(predicion)
#Esto daría unha probabilidad cercana a 1, xa que 97 é maior que 50.
#Se probas con un número como 30, obterás un valor cercano a 0.
EXPLICACIÓN EPOCHS E batch_size e como afecta á precisión da predición
Épocas (epochs): As épocas indican cantas veces o modelo verá todos os datos de adestramento de principio a fin durante o adestramento. É como repetir unha tarefa varias veces para asegurarte de aprendela ben.
Exemplo : Supoñamos que tes un libro de 100 páxinas (os datos de adestramento). Se les todas as páxinas unha vez, iso é 1 época. Se les o libro completo 10 veces, completaches 10 épocas.
No contexto do modelo: Se epochs=5, o modelo procesa os mesmos datos completos 5 veces para axustar os seus parámetros e mellorar o seu rendemento.
Más épocas permiten que o modelo aprenda máis, pero demasiadas poderían facer que "memorice" os datos e non funcione ben con datos novos (sobreaxuste).
Tamaño de Lote (batch_size): O tamaño de lote indica cantos datos procesa o modelo á vez durante o adestramento. Dividir os datos en pequenos grupos ou "lotes" axuda ao modelo para aprender de maneira máis eficiente.
Exemplo : Supoñamos que tes 1000 datos (por exemplo, números entre 0 e 9). Se o batch_size=100, o modelo procesará os datos en grupos de 100: Primeiro analiza os primeiros 100 números, axusta os seus parámetros e logo pasa ao seguinte grupo de 100, e así sucesivamente.
No contexto do modelo: Se batch_size=32, o modelo verá 32 datos á vez, actualizará os seus parámetros e logo pasará aos seguintes 32.
Un tamaño de lote máis pequeno pode facer que a aprendizaxe sexa máis detallado pero máis lento, mentres que un lote máis grande é máis rápido, pero o modelo pode ser menos preciso.
Relación entre Épocas e Tamaño de Lote:
Se tes 1000 datos,
Se batch_size=100 e epochs=5, o modelo procesará os datos en grupos de 100. Como hai 10 lotes (1000 / 100), fará 10 axustes por época.
Ao final de 5 épocas, realizaría 50 axustes en total.
epochs: Cantas veces repasamos todos os datos.
batch_size: Cantos datos procesamos á vez.
A taxa de aprendizaxe (learning rate) é un dos parámetros máis importantes nun modelo de aprendizaxe automática.
Define canto modifican as neuronas os seus pesos en cada iteración para mellorar as súas predicións.
Exemplo : Imaxina que estás aprendendo a lanzar unha pelota a unha canastra. Se cada intento axustas moito a forza e a dirección, podes acabar fallando moito. Se axustas demasiado pouco, tardarás moito en mellorar.
A taxa de aprendizaxe funciona do mesmo xeito: se é demasiado alta, pode saltar os valores correctos, e se é demasiado baixa, pode aprender moi lentamente.
Como afecta ao modelo?
Taxa de aprendizaxe alta (learning rate = 0.1 ou máis)
O modelo cambia moito os pesos en cada iteración.
Aprende rápido, pero pode ser inestable e non atopar a mellor solución.
Posible problema: O erro oscila e non baixa correctamente.
Taxa de aprendizaxe baixa(learning rate = 0.001 ou menos)
O modelo axusta os pesos moi lentamente.
Aprende con máis estabilidade pero pode tardar moito en mellorar.
Posible problema: Precísanse moitas épocas para obter bos resultados.
Como elixir a taxa correcta?
Probas típicas: Comezar cun valor medio, como 0.01, e probar con valores maiores ou menores.
Se o modelo aprende demasiado lento, probar 0.05 ou 0.1.
Se o erro flutúa moito, probar valores menores, como 0.001.
Na práctica: Moitos modelos usan taxa de aprendizaxe adaptativa, como o optimizador Adam, que axusta automaticamente a taxa durante o adestramento.
Nos programas anteriores, a taxa de aprendizaxe está presente dentro da función modelo.compile(), que define como o modelo aprenderá durante o adestramento.
Exemplo dos programas anteriores:
modelo.compile( optimizer='adam', # Optimizador 'adam' que axusta automaticamente a taxa de aprendizaxe. loss='binary_crossentropy', # Función de perda para clasificación binaria. metrics=['accuracy'] # Métrica para monitorizar a precisión do modelo. )
Onde aparece exactamente?O optimizador Adam axusta automaticamente a taxa de aprendizaxe, polo que non aparece como un número explícito no código.
Se quixésemos especificar a taxa de aprendizaxe manualmente, poderíamos facelo así:
from tensorflow.keras.optimizers import Adam
modelo.compile( optimizer=Adam(learning_rate=0.01), # Aquí establecemos a taxa de aprendizaxe en 0.01 loss='binary_crossentropy', metrics=['accuracy'] )
Se queres experimenta con diferentes valores de learning_rate para ver o impacto na aprendizaxe do modelo...
Código Python: Perda e precisión durante o adestramento e a validación
# Importamos as bibliotecas necesarias.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
import numpy as np
import matplotlib.pyplot as plt
# Xeración dos datos:
# Creamos datos de entrada e etiquetas para adestrar o modelo.
# Xeramos 1000 números aleatorios entre 0 e 9 como datos de entrada.
datos_x = np.random.randint(0, 10, size=1000)
# Creamos as etiquetas (valores esperados) en base aos datos.
# Os números maiores que 5 etiquétanse como 1, e os demais como 0.
datos_y = (datos_x > 5).astype(int)
# Creación do modelo de rede neuronal:
# Utilizamos Keras para definir un modelo secuencial cunha estrutura simple.
modelo = Sequential([
# Primeira capa: Especificamos explícitamente a entrada con Input(shape=(1,))
Input(shape=(1,)),
Dense(10, activation='relu'), # Capa oculta con 10 neuronas e activación 'relu'.
Dense(1, activation='sigmoid') # Capa de saída con 1 neurona e activación 'sigmoid'.
])
# Compilación do modelo:
# Configuramos como aprenderá o modelo durante o adestramento.
modelo.compile(
optimizer='adam', # Optimizador 'adam' para axustar parámetros automaticamente.
loss='binary_crossentropy', # Función de perda para clasificación binaria.
metrics=['accuracy'] # Métrica para monitorizar a precisión do modelo.
)
# Adestramento do modelo:
# Adestramos o modelo cos datos xerados. Aquí tamén se inclúe unha división
# para validación, de maneira que poidamos observar o progreso en datos novos.
historial = modelo.fit(
datos_x,
datos_y,
epochs=10, # Número de veces que o modelo verá os datos.
batch_size=32, # Dividimos os datos en bloques pequenos para eficiencia.
validation_split=0.2 # Usamos o 20% dos datos para validación.
)
# **Visualización do progreso:**
# Debuxamos o progreso da perda e da precisión durante o adestramento.
plt.figure(figsize=(12, 4))
# Gráfico da perda
plt.subplot(1, 2, 1)
plt.plot(historial.history['loss'], label='Perda no Adestramento')
plt.plot(historial.history['val_loss'], label='Perda na Validación')
plt.xlabel('Época')
plt.ylabel('Perda')
plt.title('Progreso da Perda')
plt.legend()
# Gráfico da precisión
plt.subplot(1, 2, 2)
plt.plot(historial.history['accuracy'], label='Precisión no Adestramento')
plt.plot(historial.history['val_accuracy'], label='Precisión na Validación')
plt.xlabel('Época')
plt.ylabel('Precisión')
plt.title('Progreso da Precisión')
plt.legend()
# Amosar as gráficas
plt.tight_layout()
plt.show()
# **Notas finais:**
# - O modelo agora pode predicir se un número aleatorio entre 0 e 9 é maior ou menor que 5.
# - Coas gráficas, podes observar como diminúe a perda e mellora a precisión ao longo das épocas.
Actividade 2: Aumentando capas
◦ Obxectivo: Entender como pode afectar o aumento de capas a unha rede neuronal ◦ Instrución: Usar Keras para realizar un modelo de 3 capas que prediga se un número é >=5.
Capa de saída: Unha neurona con activación sigmoid.
Representación do Modelo Modificado:
Entrada: Unha neurona para un só número.
Primeira capa oculta: 10 neuronas con activación relu.
Nova segunda capa oculta: 5 neuronas con activación relu.
Capa de saída: Unha neurona con activación sigmoid.
Diferéncia clave sería a nova capa oculta, que agrega máis complexidade e profundidade ao modelo.
A nova capa oculta actúa como un nivel extra de análise, o que mellora a capacidade do modelo de entender os datos pero pode desestabilizar ó ser "máis sensible". Este paso adicional no procesamento fai que sexa máis "intelixente" ao identificar patróns.
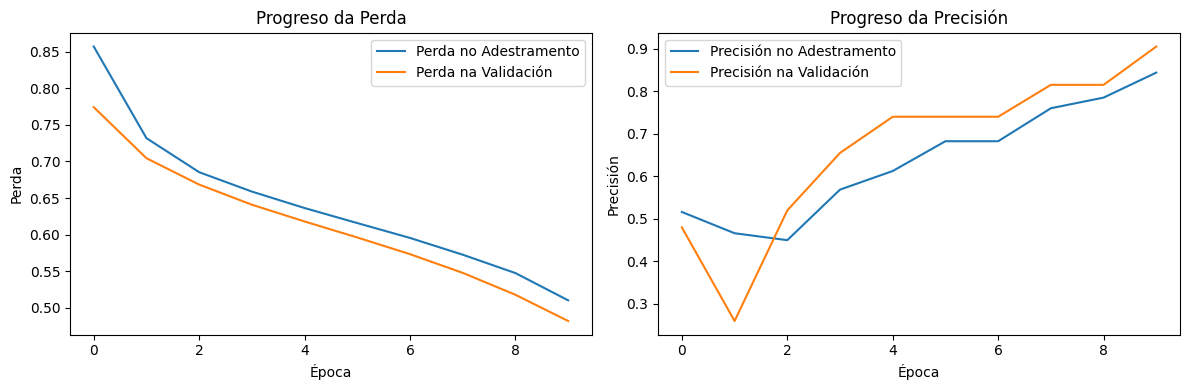
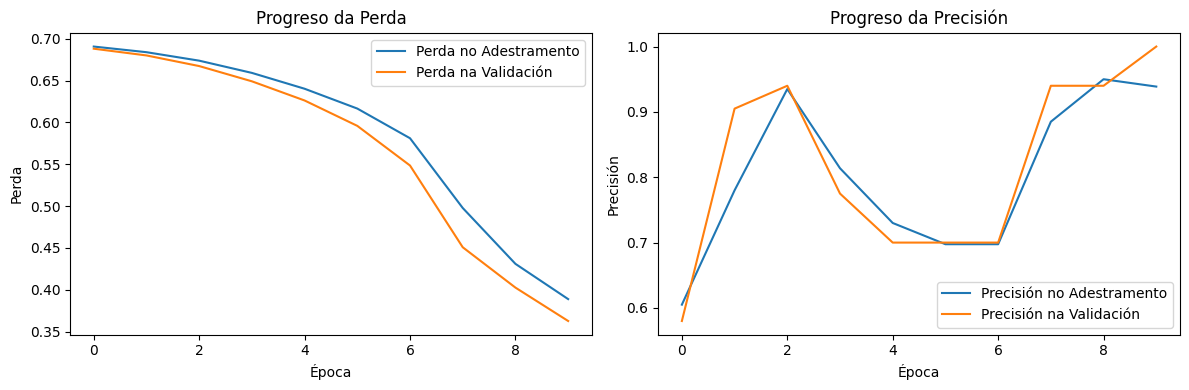
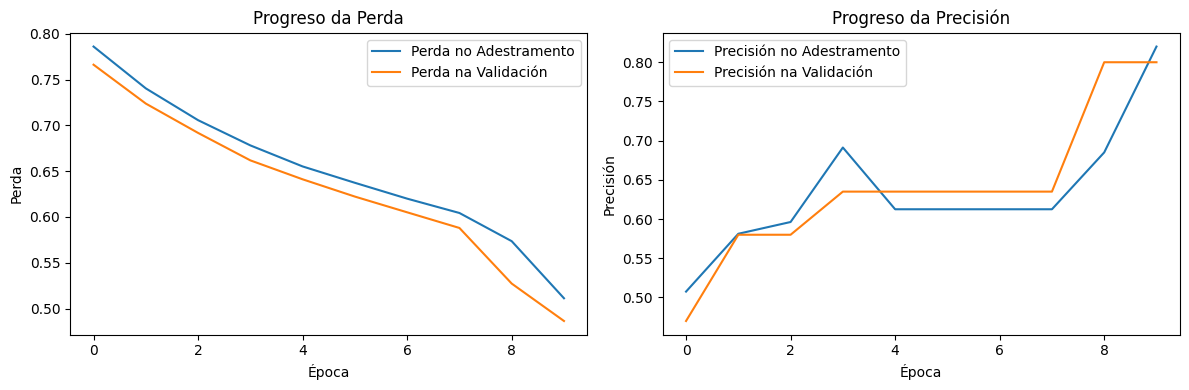
Paso 2: Evolución das gráficas a medida que se executa o adestramento e comparativa con 2 capas
A análise das 10 execucións mostra un patrón claro respecto ao impacto de engadir unha segunda capa oculta con 5 neuronas no modelo de adestramento:
Variabilidade entre execucións → En función da inicialización dos pesos e dos datos de validación, a segunda capa introduce maior sensibilidade ás condicións do adestramento, facendo que en certas execucións o modelo aprenda de forma estable, mentres que noutras mostra fluctuacións evidentes.
Impacto na curva da perda → En comparación co modelo de 2 capas, a perda no adestramento diminúe de forma similar, pero a da validación mostra máis fluctuacións en varias execucións, suxerindo que o modelo non sempre xeneraliza de maneira uniforme.
Precisión na validación → A precisión final na validación varía entre execucións, cunha tendencia xeral que mostra que o modelo con 3 capas non sempre mellora a capacidade de clasificación respecto a 2 capas, xa que en varias execucións a súa precisión é similar ou presenta fluctuacións.
Posible sobreaxuste → En certas execucións, a segunda capa parece facer que o modelo se adapte demasiado aos datos de adestramento, reducindo a súa capacidade de xeneralización, algo que pode explicarse por un maior número de parámetros que deben ser optimizados.
Optimización necesaria → Para que a segunda capa oculta realmente contribúa positivamente, sería necesario axustar hiperparámetros como a taxa de aprendizaxe ou a regularización, para evitar que o modelo se volva demasiado dependente das condicións específicas do adestramento.
Aínda que na maioría destas execucións, o modelo de 3 capas ten mellores resultados (menos perda e máis precisión),
a introdución dunha segunda capa oculta non garante unha mellora automática no modelo, e pode incrementar a súa variabilidade e sensibilidade aos datos. Isto demostra que, ao engadir complexidade a unha rede neuronal, é fundamental realizar unha análise detallada dos efectos e non asumir que "máis capas" significan "mellor rendemento". Debes entender a importancia do equilibrio entre a profundidade da rede e a estabilidade do adestramento.
Gráfica
Código Python: Modelo con 3 capas
# Importamos as bibliotecas necesarias.
# TensorFlow proporciónanos as ferramentas para crear e adestrar redes neuronais.
print("Importando TensorFlow e Keras para crear e adestrar redes neuronais...")
import tensorflow as tf
# Sequential e Dense son partes de Keras (que está integrado en TensorFlow).
# Sequential permítenos crear un modelo de rede neuronal agregando capas en orde.
# Dense engade capas densas ao noso modelo, que son capas onde cada neurona está conectada con todas as da capa anterior.
print("Importando Sequential e Dense de Keras para construír a rede neuronal...")
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
# Importamos NumPy, que é unha ferramenta para traballar con números e xerar datos de proba.
print("Importando NumPy para xerar datos de entrada...")
import numpy as np
# Importamos Matplotlib para visualizar os resultados do adestramento do modelo.
print("Importando Matplotlib para xerar gráficas...")
import matplotlib.pyplot as plt
# Xeración dos datos.
# Creamos datos de entrada e etiquetas para adestrar o modelo.
# Xeramos 1000 números aleatorios entre 0 e 9 como datos de entrada.
print("Xerando 1000 números aleatorios entre 0 e 9 para adestrar o modelo...")
datos_x = np.random.randint(0, 10, size=1000)
# Creamos as etiquetas (valores esperados) en base aos datos.
# Os números maiores que 5 etiquétanse como 1, e os demais como 0.
print("Asignando etiquetas aos datos (1 se é maior que 5, 0 se non)...")
datos_y = (datos_x > 5).astype(int)
# Creación do modelo de rede neuronal.
# Utilizamos Keras para definir un modelo secuencial cunha estrutura simple.
print("Creando o modelo da rede neuronal...")
modelo = Sequential()
# Primeira capa: Especificamos explícitamente a entrada con Input(shape=(1,))
print("Engadindo a capa de entrada...")
modelo.add(Input(shape=(1,)))
# Primeira capa oculta con 10 neuronas e activación 'relu'.
print("Engadindo a primeira capa oculta con 10 neuronas e activación 'relu'...")
modelo.add(Dense(10, activation='relu'))
# Segunda capa oculta con 5 neuronas e activación 'relu'.
print("Engadindo unha segunda capa oculta con 5 neuronas e activación 'relu'...")
modelo.add(Dense(5, activation='relu'))
# Capa de saída con 1 neurona e activación 'sigmoid'.
print("Engadindo a capa de saída con activación 'sigmoid'...")
modelo.add(Dense(1, activation='sigmoid'))
# Compilación do modelo.
# Configuramos como aprenderá o modelo durante o adestramento.
print("Compilando o modelo con optimizador 'adam' e función de perda 'binary_crossentropy'...")
modelo.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
# Adestramento do modelo.
# Adestramos o modelo cos datos xerados. Aquí tamén se inclúe unha división
# para validación, de maneira que poidamos observar o progreso en datos novos.
print("Adestrando o modelo con 10 épocas e validación do 20% dos datos...")
historial = modelo.fit(
datos_x,
datos_y,
epochs=10,
batch_size=32,
validation_split=0.2
)
# Visualización do progreso.
# Debuxamos o progreso da perda e da precisión durante o adestramento.
print("Xerando os gráficos de perda e precisión...")
plt.figure(figsize=(12, 4))
# Gráfico da perda
plt.subplot(1, 2, 1)
plt.plot(historial.history['loss'], label='Perda no Adestramento')
plt.plot(historial.history['val_loss'], label='Perda na Validación')
plt.xlabel('Época')
plt.ylabel('Perda')
plt.title('Progreso da Perda')
plt.legend()
# Gráfico da precisión
plt.subplot(1, 2, 2)
plt.plot(historial.history['accuracy'], label='Precisión no Adestramento')
plt.plot(historial.history['val_accuracy'], label='Precisión na Validación')
plt.xlabel('Época')
plt.ylabel('Precisión')
plt.title('Progreso da Precisión')
plt.legend()
# Amosar as gráficas
plt.tight_layout()
plt.show()
# Notas finais.
# O modelo agora pode predicir se un número aleatorio entre 0 e 9 é maior ou menor que 5.
print("O modelo está listo para predicir se un número entre 0 e 9 é maior ou menor que 5!")
# Coas gráficas, podes observar como diminúe a perda e mellora a precisión ao longo das épocas.
print("Observa como evoluciona o modelo con cada época: perda diminuíndo e precisión aumentando!")
Unha capa oculta axuda a o modelo para identificar patróns en os datos.
Pensa en cada neurona como un novo traballador.Cada neurona analiza unha parte do problema e atopa pequenas pistas (patróns).Ao combinar as neuronas, o modelo pode identificar patróns máis complexos.
Cando engadimos unha nova capa oculta, estamos a dicir: "Hei, imos deixar que outro grupo de traballadores (neuronas) analice as pistas que atopou a primeira capa para que podamos descubrir algo máis profundo.
Exemplo : Supoñamos que o modelo tenta determinar se un número é maior que 5. Isto é o que ocorre:
Cunha soa capa oculta (modelo orixinal):As neuronas desa capa traballan xuntas para aprender unha regra simple, como "Se o número é maior a 5, etiqueta como 1." Funciona, pero ten menos flexibilidade para aprender regras máis complexas.
Con dúas capas ocultas (modelo modificado):
Primeira capa: Atopa patróns básicos, como: "O número está máis preto de 0." "O número está máis preto de 10."
Segunda capa: Usa eses patróns para facer unha análise máis detallada, como: "Se o número é claramente maior a 5 segundo a capa anterior, etiqueta como 1." Esta segunda capa permite axustar máis finamente como decide o modelo.
Más capas e neuronas permiten ao modelo captar relacións máis complicadas entre os datos.
Actividade 3: Aumentar neuronas
◦ Obxectivo: Entender como pode afectar o aumento de neuronas nas capas de unha rede neuronal ◦ Instrución: Usar Keras para realizar un modelo de 2 capas con 50 neuronas na capa oculta que prediga se un número é >=5.
Paso 1: Modelo con 50 neuronas
Código con máis neuronas , imos cambiar o número de neuronas na primeira capa oculta de 10 a 50 (na segunda capa ten que ser 1 porque a saída é 1 ou 0).
Volvemos ao modelo orixinal con 2 capas (unha capa oculta e unha capa de saída), onde analizaremos o efecto de aumentar o número de neuronas na capa oculta e graficaremos os resultados de novo.
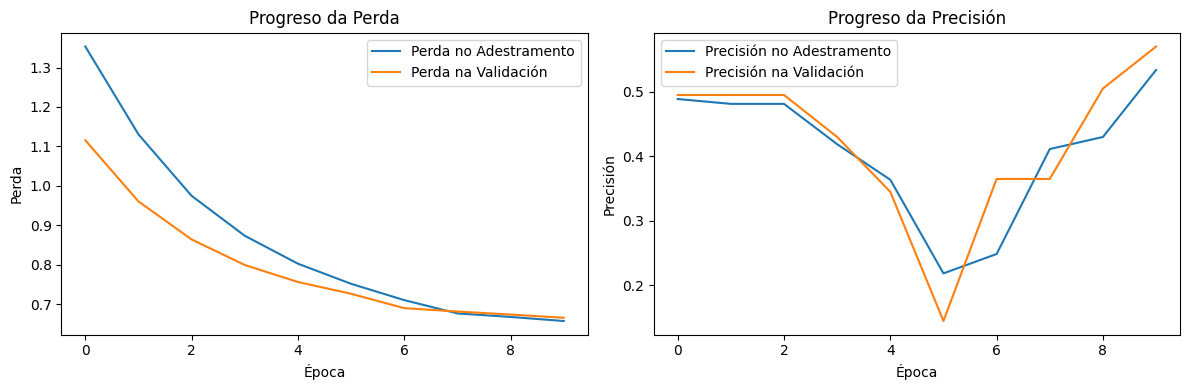
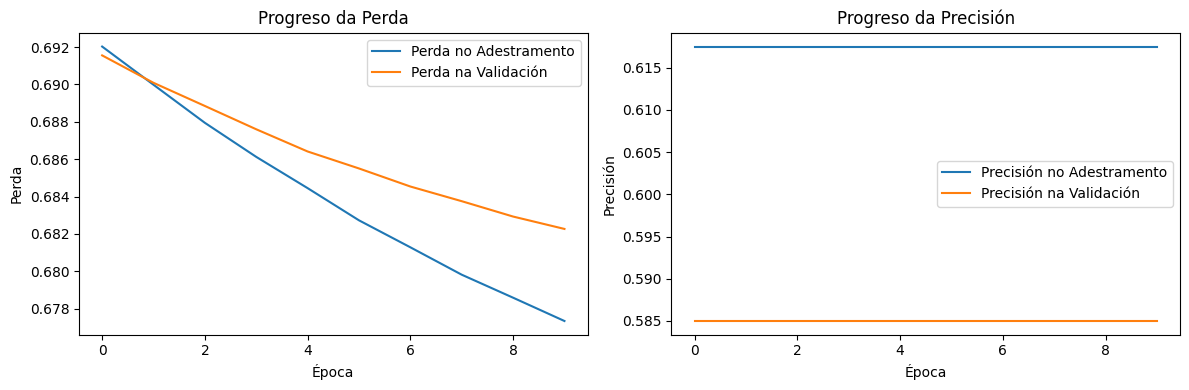
A cantidade de neuronas incrementouse de 10 a 50. Isto significa que a capa oculta ten máis parámetros (pesos e rumbos) que pode axustar durante o adestramento.Máis neuronas permiten ao modelo aprender patróns máis complexos e sutís dos datos. O modelo será máis "potente" e terá máis capacidade para axustar as súas predicións. Con todo, pode tomar un pouco máis de tempo adestrarse debido ao aumento nos cálculos.
Resultados esperados
Gráfica da perda (Loss): A perda final debería ser máis baixa que con menos neuronas, xa que o modelo é capaz de aprender máis patróns. A perda pode diminuír máis lentamente a o inicio debido a a complexidade adicional.
Gráfica da precisión (Accuracy): A precisión final pode ser máis alta tanto en os datos de adestramento como de validación. Se hai unha gran diferenza entre adestramento e validación, podería indicar un risco de sobreaxuste (é dicir, o modelo axústase demasiado a os datos de adestramento e non xeneraliza ben).
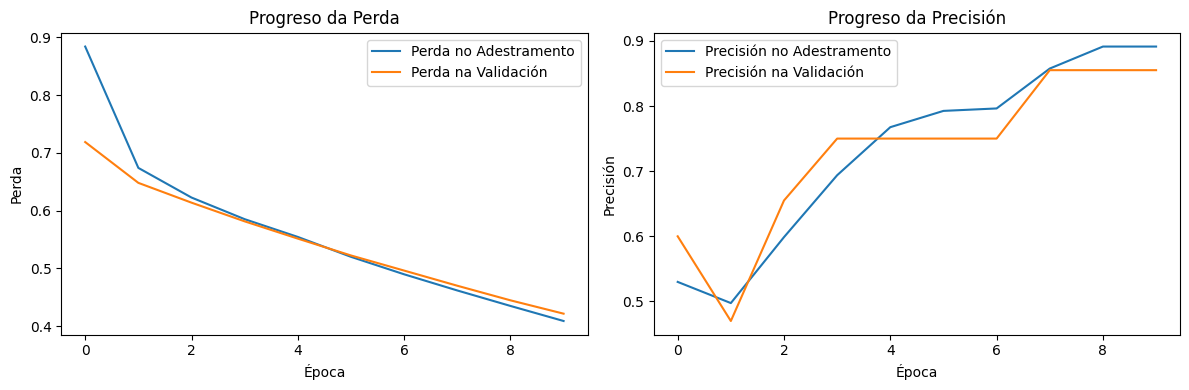
Paso 2:Comparativa das gráficas
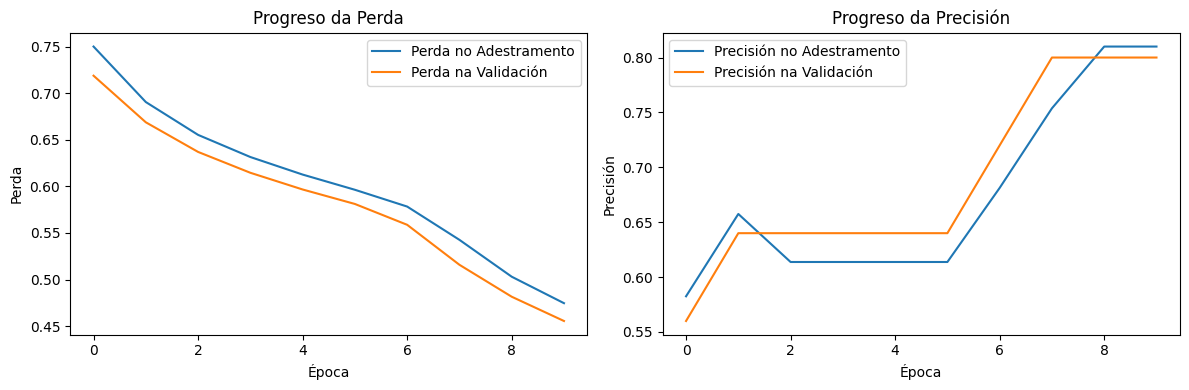
Creación propia. Rede con 2 capas e 10 neuronas(CC BY-SA)
Creación propia. Rede con 2 capas e 50 neuronas(CC BY-SA)
Característica
10 Neuronas
50 Neuronas
Perda no adestramento (última época)
Valor máis alto, aprendizaxe máis gradual
Perda máis baixa, aprendizaxe rápida
Perda na validación (última época)
Estable pero lixeiramente máis alta
Baixa, pero con fluctuacións
Precisión no adestramento (última época)
Menos pronunciada, progresión gradual
Máxima precisión, progreso rápido
Precisión na validación (última época)
Menor que 50 neuronas, pero estable
Moi alta, pero con oscilacións
Impacto na estabilidade
Máis control sobre a xeneralización
Maior sensibilidade ao sobreaxuste
A rede con 50 neuronas aprende máis rápido, mostrando unha mellora notable na precisión e unha maior caída na perda, pero tamén pode ser máis propensa ao sobreaxuste. A rede con 10 neuronas avanza de forma máis estable, pero con unha mellora menos agresiva, o que pode significar maior control sobre a xeneralización pero menos capacidade de adaptación aos datos. Se a meta é maximizar a precisión sen perder estabilidade, pode ser interesante axustar regularización ou taxa de aprendizaxe para que a rede con máis neuronas non sobreaxuste.
Aumentar as neuronas permite un maior axuste ao conxunto de adestramento, pero tamén pode facer que o modelo dependa máis dos seus datos iniciais, afectando a súa estabilidade en validación.
Código Python: Red neuronal de 2 capas con 50 neuronas na 2ª capa
# Importamos as librarías necesarias
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
import numpy as np
import matplotlib.pyplot as plt
# Xeración dos datos
datos_x = np.random.randint(0, 10, size=1000)
datos_y = (datos_x > 5).astype(int)
# Modelo básico con 2 capas
modelo = Sequential([
Input(shape=(1,)), # Capa de entrada
Dense(50, activation='relu'), # Capa oculta con 50 neuronas
Dense(1, activation='sigmoid') # Capa de saída
])
# Compilación do modelo
modelo.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
# Adestramento do modelo
historial = modelo.fit(
datos_x,
datos_y,
epochs=10, # 10 épocas para observar o progreso
batch_size=32,
validation_split=0.2 # Usamos un 20% para validación
)
# Gráfica do progreso
plt.figure(figsize=(12, 4))
# Gráfica da perda
plt.subplot(1, 2, 1)
plt.plot(historial.history['loss'], label='Perda no Adestramento')
plt.plot(historial.history['val_loss'], label='Perda na Validación')
plt.xlabel('Época')
plt.ylabel('Perda')
plt.title('Progreso da Perda')
plt.legend()
# Gráfica da precisión
plt.subplot(1, 2, 2)
plt.plot(historial.history['accuracy'], label='Precisión no Adestramento')
plt.plot(historial.history['val_accuracy'], label='Precisión na Validación')
plt.xlabel('Época')
plt.ylabel('Precisión')
plt.title('Progreso da Precisión')
plt.legend()
# Amosar as gráficas
plt.tight_layout()
plt.show()